
Last Updated on 2024年8月9日 by らくろぐ
ちょっとしたデータ解析や文字列操作などに向いているPython。今回は適当な文字列テキストデータからcsv形式に変換出力するサンプルプログラムを作成したので紹介します。
Contents
PythonによるCSV出力サンプルプログラム
サンプルファイルは以下のようなものとします。
import csv
datafile = 'test.txt'
outfile = 'test_out.csv'
with open(datafile,"r") as f:
# print(f.read())
# total_lines = sum(1 for line in f)
datalist = f.readlines()
a = True
#print(total_lines)
i = 0
with open(outfile, 'w') as file:
writer = csv.writer(file)
writer.writerow(['l', 'r'])
while a:
if not datalist:
a = False
break
temp =datalist[i]
if temp.find('Testa')!=-1:
print(temp)
row1 = datalist[i]
while a:
if not datalist:
a = False
temp = datalist[i]
if temp.find('Testc')!= -1:
print(temp)
row2 = datalist[i]
writer.writerow([row1, row2])
break
i +=1
i += 1
print('count:{0}'.format(i))
f.close()
file.close()作ろうと思ったきっかけ
業務で使用しているlogファイルが結構なボリュームがあり、そこから必要なデータ部分のみ抽出するのが結構手間だったためです。またpythonの勉強も兼ねたかったので、サンプルを探してカスタマイズしてみました。
今回のサンプルプログラムでは、変換元となるテキストデータは以下のように形であるとします。
その中でTestaの行とTestcの行を抜き出し、csv形式で出力します。
Testa=aaa,Testb=bbb
Testc=ccc,Testd=ddd
Teste=eee,Testf=fff
Teste=ggg,Testh=hhh
Testa=aaa,Testb=bbb
Testc=ccc,Testd=ddd
Teste=eee,Testf=fff
Teste=ggg,Testh=hhh
Testa=aaa,Testb=bbb
Testc=ccc,Testd=ddd
Teste=eee,Testf=fff
Testa=aaa,Testb=bbb
Testc=ccc,Testd=ddd
Teste=ggg,Testh=hhh
Teste=eee,Testf=fff
Testa=aaa,Testb=bbb
Testc=ccc,Testd=ddd結果はこうなります。
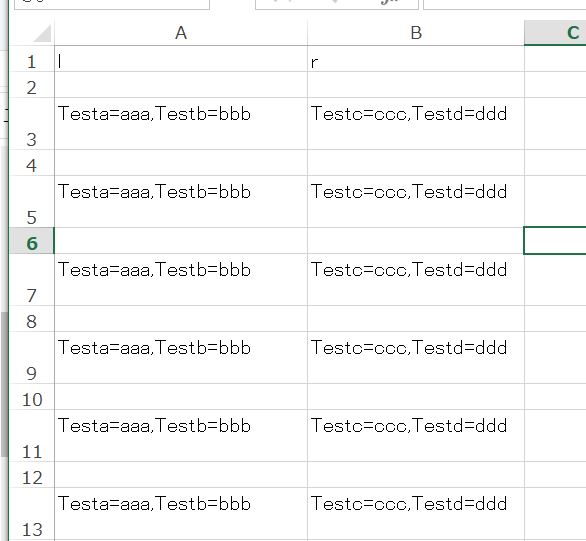
Pythonサンプルプログラムの解説
入出力ファイル名
datafile = 'test.txt' #入力ファイル outfile = 'test_out.csv' #出力ファイル
入力/出力ファイルは合わせて変更してください。
ファイルを1行単位で読み込む
with open(datafile,"r") as f:
datalist = f.readlines()入力ファイルを読み込み専用で開き、1行単位で変数(datalist)へ入力します。
CSV形式の出力ファイルの準備
with open(outfile, 'w') as file:
writer = csv.writer(file)
出力ファイルを書き込みで開き、csv形式で書き込むように設定
まず最初の行に要素のラベルを書き込んでいます。
writer.writerow(['l', 'r'])
ファイルの最後まで読み出す処理
ファイルの終端まで読み出す処理(言い換えると終端で処理を終了する)は以下の部分で判定しています。
while a:
if not datalist:
a = False
データが存在中はa=Trueなので処理を継続。
都度、datalistがデータかどうか判別し、データなければ終端としてa=Falseに変更し、whileを抜けるようにします。
行単位でデータが読み込めたら、その後の処理を実施します。
datalist[i]のiは行単位の配列。行数分配列が作られます。
文字列の検索
取得した配列の文字列検索は以下で行っています。文字列の中に’Testa’があるかどうかの判別。
if temp.find('Testa')!=-1:
検索結果が一致した場合のみ、csvの要素1(row1)として設定。
文字列の検索はserchなども使えます。
文字列の表示
以下の行はループしている行を便宜的に表示している部分です。
print('count:{0}'.format(i))
{}の後ろに.fomat()を付け、表示したい変数を渡すというフォーマットです。
コンソールの出力には以下のような形で見えます。
Testa=aaa,Testb=bbb Testc=ccc,Testd=ddd count:2 count:3 count:4 Testa=aaa,Testb=bbb
Pythonによるテキストデータ抽出とCSV変換サンプルプログラム、まとめ
Phtyonによるテキストデータ抽出とCSV変換プログラムについて簡単な解説を行いました。入出力のファイル名が固定だったり、抽出する文字列が固定だったりして、拡張性をつけるには改善の余地がまだまだありますが、業務改善の一歩に結びつけていければと思っています。以上、参考になればうれしいです。




